翻译|微软翻译新增对 12 种新语言/方言支持
IT之家 10 月 12 日消息,微软翻译今天宣布支持 12 种新的语言和方言。有了这项支持,微软翻译现在总共支持 103 种语言,覆盖了世界人口的 72%。有了这个版本,微软翻译服务可以将文本和文件翻译成全世界 56.6 亿人所使用的本土语言。
文章插图
IT之家获悉,微软翻译新增加的语言是巴什基尔语、迪维希语、格鲁吉亚语、吉尔吉斯语、马其顿语、蒙古语(西里尔语)、蒙古语(传统版)、塔塔尔语、藏语、土库曼语、维吾尔语和乌兹别克语(拉丁语)。这些新语言有 8460 万人使用。
微软技术研究员和 Azure 人工智能首席技术官黄学东说:“一百种语言对我们来说是一个很好的里程碑,可以实现我们的雄心壮志,让每个人无论说什么语言都能进行交流。”
微软翻译的演变20 多年前,微软研究院首次开发了机器翻译系统。2003 年,一个机器翻译系统将整个微软知识库从英文翻译成西班牙文、法文、德文和日文,并将翻译内容发布在其网站上,成为当时互联网上最大的面向公众的原始机器翻译应用。
微软在统计机器翻译(SMT)模型的基础上进一步发展了这些系统,并通过 Windows Live Translator、Translator API 以及微软 Office 应用程序的内置功能向公众提供。
微软表示,多年来,我们为世界上许多最常用的语言增加了翻译系统。随着人工智能(AI)技术的发展,微软采用了神经机器翻译(NMT)技术,并将所有机器翻译系统迁移到基于 Transformer 技术的神经模型上,实现了翻译流畅性和准确性的巨大提升。
虽然 NMT 技术显著提高了整体翻译质量,但 Transformer 架构的出现为创建机器翻译模型铺平了新的道路,使其能够用比以前更少的材料进行训练。使用多语言 Transformer 架构,现在可以用其他语言的材料来增加训练数据,通常是在同一或相关的语言家族中,为数据量小的语言制作模型,通常被称为低资源语言。
即使有了这些技术,也必须要有一套目标语言的数字文件,以及另一种已经包括在内的语言的翻译--通常被称为 parallel 文件。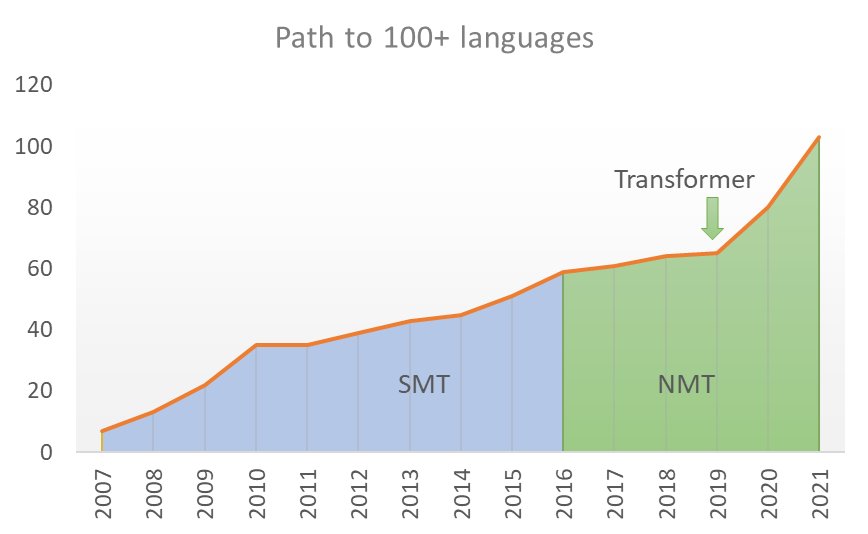
文章插图
▲ 微软翻译所翻译的语言数量折线图,从 2007 年的 7 种到 2021 年的 100 多种。该系统从 2007 年到 2016 年一直使用统计机器翻译(SMT)。2016 年采用神经机器翻译(NMT)技术有助于提高翻译质量,2019 年采用 Transformer 架构,使微软团队能够用较少的数据量为低资源语言建立模型。
在增加新语言时,微软表示,最大的挑战之一是获得训练和制作机器翻译模型所需的足够的双语数据。这些数据由高质量的人工翻译内容组成,既包括想要添加的语言,也包括该服务已经支持的语言之一。对于许多语言来说,这种双语数据是很难获得的,特别是对于数字资源不足或濒临灭绝的语言。
微软称,很幸运与语言社区的伙伴合作,他们可以获得人工翻译的文本,并可以帮助收集资源不足的语言的数据。这些社区合作伙伴,通常是与他们各自社区合作的志愿者,通过咨询社区成员,不辞辛苦地收集双语句子。然后,他们评估所产生的机器翻译模型的质量。
文章插图
Azure 认知服务翻译在微软产品中公开了 NMT 模型,并通过文本翻译和文档翻译 API 向翻译客户公开。这些 API 将纯文本和复杂文件从一种语言翻译成另一种语言。Azure 认知服务翻译器 API 可在公共云和安全的微软 Azure 政府云中使用。此外,文本翻译 API 在 Docker 容器中可用,允许客户在企业内部处理内容以满足特定的监管要求。
- m都是大片!微软 Skype 支持将必应 Bing 图片设为通话虚拟背景
- OpenHarmony 项目群 12 月新增捐赠人美的集团、深圳开鸿
- 打脸!华为在美国,用专利把英特尔、苹果、微软、高通打败了
- 华为|iOS15.2.1 正式版发布:新增 6 项改进
- Windows|如果美国让微软断供中国windows系统,不会出现什么影响
- 微软 Win11 你的手机 App 更新:圆角外观,界面更简洁
- 微信聊天最令人头疼的场景是什么?一定有人会说是对方发来一连串语音还都是超过30秒的长消息...|终于!微信新增语音暂停功能,60秒长语音不用重头再
- intel公司|苹果芯片总监刚被Intel挖走,技术大咖又跳槽微软
- 微软|如果微软立刻远程让我国所有电脑的停止运行windows,怎么办?
- MIUI|MIUI13公测版来了,6大新增功能,让你的手机焕然一新!