在高并发的情况下 , 数据库的性能会显著下降 。 因此我们有必要针对高并发的场景下 , 对于数据库进行性能优化 。
常见的优化方式有以下几种:
一、增加缓存
增加缓存包括增加外部缓存和增加数据库查询缓存两种 。 外部缓存例如使用内存数据库Redis , 开发人员将一些固定的数据读取Redis中 , 直接在其中查询 , 从而避免对数据库进行IO操作 , 节省系统开销 。
增加数据库缓存 , 以MySql为例 , 可以在my.cnf中 , 添加以下配置:
query_cache_size=256M
query_cache_limit=10M
query_cache_type=1
注意 , 配置之后需要重启数据库 。
其中query_cache_size为总缓存大小 , 官方推荐值不大于256M 。
query_cache_limit为单条查询结果的最大缓存大小 , 如不设置 , 默认为1M 。
query_cache_type表示缓存方式 , 0表示不开启缓存 , 1表示每条语句都开启缓存(除非指定不需要缓存) , 2表示如果查询语句中指定使用缓存 , 则进行缓存 。 具体如下所示:
SELECT SQL_CACHE ... FROM ... WHERE ... 在type设置为2时 , 采用该语句可以进行缓存 。
SELECT SQL_NO_CACHE ... FROM ... WHERE ... 在type设置为1时 , 采用该语句可以不进行缓存 。
对于一些变化频率较低的表的查询中 , 开启缓存可以对性能起到一定提升作用 。
二、垂直分库
数据库垂直拆分 , 是指按照业务对数据库表进行分类 , 将相关的表放到同一个数据库上 。 例如在一个网上商城系统中 , 可以将用户相关表、订单相关表、物流信息相关表各自独立放在自己的库上 。 这样可以使业务逻辑更为清晰 , 也使得数据库易维护、易扩展 。 但是可能引起一些跨库事务的问题 。 而且部分表关系原本可以通过联合查询来实现 , 垂直分库后只能通过服务间相互调用来完成 。
三、水平分库
通常来讲应先进行垂直拆分 , 当垂直拆分之后性能瓶颈依然存在的话 , 可以考虑继续进行水平拆分 。 水平拆分可以根据具体的业务类型来拆分 , 例如可以对用户注册时间进行拆分 , 每一年注册的用户放在不同的表里 , 或者是对用户的区域进行拆分 , 不同地区的用户放在不同的表里 , 等等 。
这种拆分的好处在于 , 可以保证单个库的容量可控 , 每条记录都是完整的 , 数据关系可以通过Join联合查询 。
其缺点在于 , 拆分规则需要编码到程序里 , 增加了系统维护的难度 , 以及不同业务的分区交互需要统筹设计 。
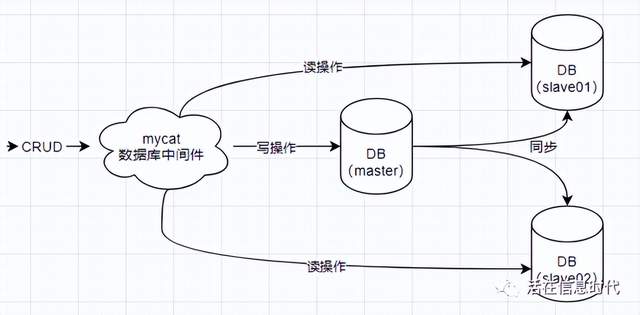
四、读写分离
所谓读写分离 , 就是将数据库分为主从库 , 主库用于写数据 , 而多个从库则用来读取数据 。 通常来讲 , 写数据库的操作要远远少于读数据库 , 所以在实践中 , 往往用于读取数据的从库数量要远大于主库 。
以MySql为例 , 需要在my.cnf中进行配置 。 具体方法如下:
在主数据库中:
server-id=1 //设置mysql的id标识
log-bin=/var/lib/mysql/mysql-bin //log-bin的日志文件 , 主从备份就是用这个日志记录来实现的
#binlog-do-db=mysql1 #需要备份的数据库名 , 如果备份多个数据库 , 重复设置这个选项 即可
#binlog-ignore-db=mysql2 #不需要备份的数据库名 , 如果备份多个数据库 , 重复设置这 个选项即可
#log-slave-updates=1 #这个参数当从库又作为其他从库的主库时一定要加上 , 否则不会给更新的记录写到binglog里二进制文件里
#slave-skip-errors=1 #是跳过错误 , 继续执行复制操作(可选)
【it芯片|程序员应知应会之高并发情况下的数据库性能优化】
- 芯片|为什么一些国产手机宁愿使用高通芯片,却不用国产的紫光系列了?
- 戴尔|国产操作系统兼容多种芯片架构,可望替代美国软硬件体系
- 芯片|芯片关键材料涨价十倍!俄做出新决定后,国产拿下全球45%市场!
- 日本抱大腿,联合美国建造2nm芯片基地!或为了摆脱台积电?
- 微软|实力被低估了?国产芯片巨头跳过192层,直接切入232层闪存生产
- 实力被低估了?国产芯片巨头跳过192层,直接切入232层闪存生产
- 程序员|腾讯与敦煌研究院成立数字实验室,这是又要出新皮肤了吗?
- 美媒:尽管美国全力阻挠,但依旧无法遏制中国芯片崛起!
- 芯片|显示器刷新频率60和144区别大吗
- 海尔|程序员的八年工资变动,令网友羡慕不已:你一个月顶我一年工资