文章插图
作者 | Ben Dickson
编译 | 琰琰
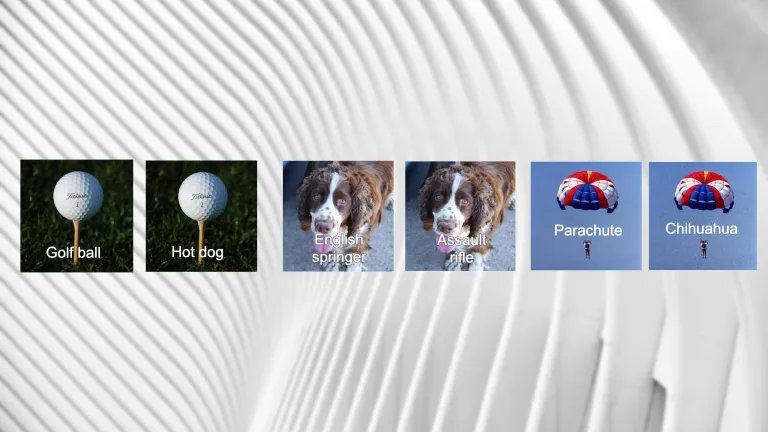
机器学习在应用程序中的广泛使用,引起了人们对潜在安全威胁的关注。对抗性攻击( adversarial attacks)是一种常见且难以察觉的威胁手段,它通过操纵目标机器学习模型,可能会“悄悄”破坏许多数据样本。基于此,对抗性机器学习(Adversarial machine learning)成为了人工智能领域的热点研究之一,越来越多的AI讲座和研讨会开始探讨这一主题,防止机器学习模型对抗攻击的新方法也在不断推陈出新。近日,来自卡内基梅隆大学和KAIST网络安全研究中心的研究团队提出了一种新的技术方法,他们试图引入无监督学习来解决当前对抗性攻击检测所面临的一些挑战。实验表明,利用模型的可解释性和对抗攻击之间的内在联系,可以发现哪些数据样本可能会受到了对抗干扰。目前,这项研究方法已受邀在2021 KDD(Knowledge Discovery and Data Mining)对抗性机器学习研讨会(AdvML)上进行了展示。假设对抗性攻击的目标是图像分类器——使图像标签从“狗”更改为“猫”。攻击者会从未经修改的“狗”图像开始。当目标模型在处理该图像时,它会返回所训练的每个类别的置信度分数列表。其中,置信度最高的类代表图像所属的类别。
文章插图
为了使这一过程反复运行,攻击者会向图像中添加少量随机噪声。由于修改会对模型的输出产生微小的变化,攻击者通过多次重复该过程可达到一个目的,即使主置信度得分降低,目标置信度得分升高。如此一来,机器学习模型便可能将其输出从一个类更改为另一个类。一般来讲,对抗攻击算法会有一个epsilon参数,这个参数可以限制模型对原始图像的更改量。但epsilon参数的对抗干扰的程度,对人眼来说仍然难以察觉。
文章插图
此外,保护机器学习模型免受对抗性攻击的方法已经有很多,但大多数方法在计算、准确性或可推广性方面会带来相当大的成本。例如,有些方法依赖于有监督的对抗训练。在这种情况下,防御者必须生成大量的对抗性样本,并对目标网络进行微调,才能正确分类修改后的示例。这种方法所生成的样本和训练成本是相当高的,而且在一定程度上会降低目标模型在原始任务上的性能。更重要的,它也不一定能够对抗未经训练的攻击技术。另外,其他的防御方法需要训练单独的机器学习模型来检测特定类型的对抗性攻击。这样虽然有助于保持目标模型的准确性,但不能保证对未知攻击技术是有效的。在这项研究中,CMU和KAIST的研究人员发现了对抗性攻击和可解释性之间的内在联系。在许多机器学习模型中,特别是深度神经网络,由于涉及大量参数,其推理和决策过程很难被追踪。因此,我们常称机器学习模型内部就像是黑匣子,具有难以解释性。这也导致其在应用范围在受到了一定的限制。