尤洋|2天训练出15亿参数大模型,国产开源项目力克英伟达Megatron-LM( 二 )
值得一提的是,Colossal-AI的API接口是可以定制的,这使得它可以便捷添加新的并行维度。
其次,大规模优化器也是Colossal-AI的亮点。
上面我们也提到了,在分布式并行系统中会使用多种并行方法,数据并行则是另一种常见方法。
这种方法的原理不难理解,就是把训练数据划分成若干份,让不同的机器运算不同的数据,然后通过一个参数服务器 (Paremeter Server)收集目标数据。
由此可以大幅提升AI模型训练过程中的批量大小,加速训练过程。
不过大批量训练有个“通病”,就是会产生泛化误差 (Generalization Gap),导致网络泛化能力下降,进而导致AI模型准确度下降。
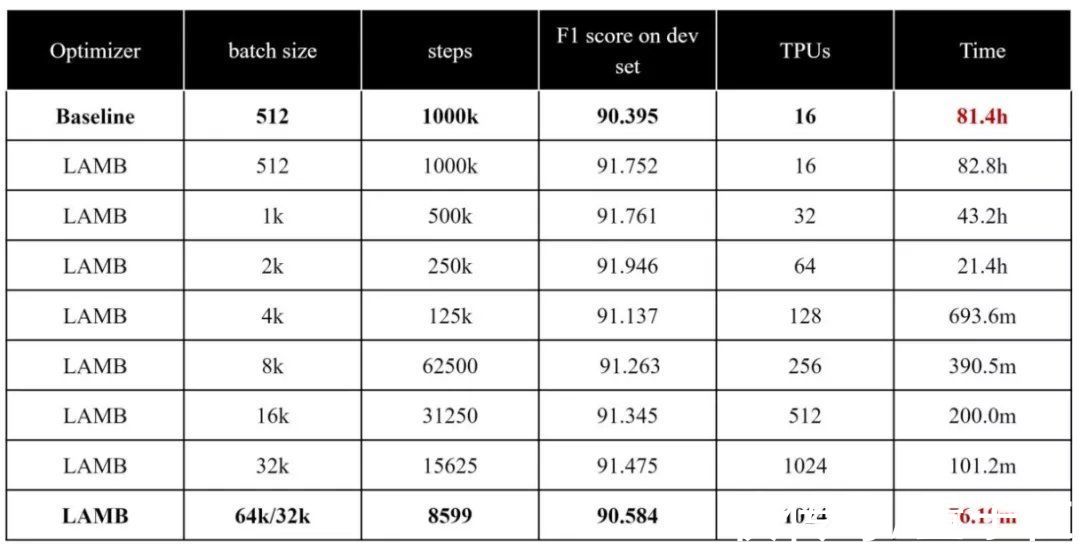
所以,Colossal-AI在系统中使用了自研的LAMB、LARS等大规模优化器。在保证训练精度的情况下,还将批大小从512扩展到65536。
其中,LARS优化器是通过逐层调整学习率,来减少因为学习率导致的无法收敛情况。
LAMB优化器则是在LARS的基础上,将逐层调整学习率的思想应用到自适应梯度上。
由此,LAMB能够很好解决此前LARS在BERT训练中存在差异的问题,最大批量达到了64K。
此前,LAMB优化器曾成功将预训练一遍BERT的时间,从原本的三天三夜缩短到一个多小时。
文章插图
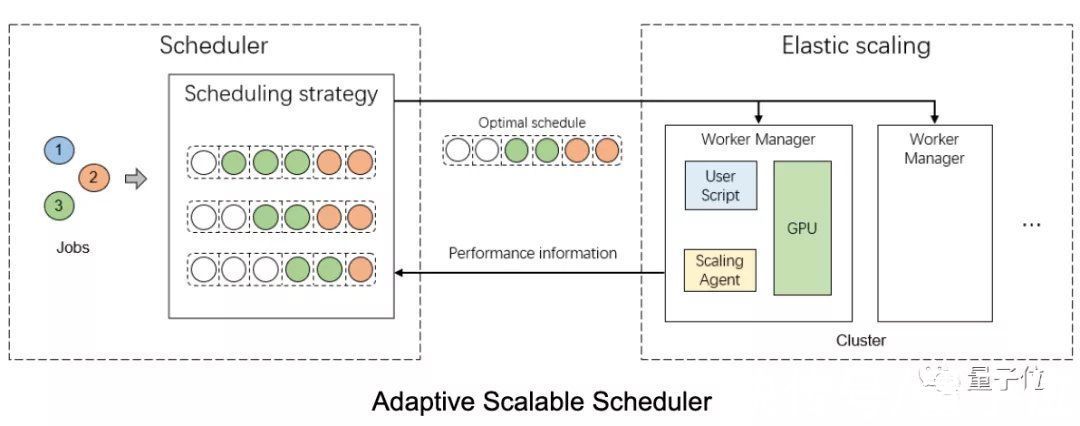
第三方面,Colossal-AI使用自适应可扩展调度器来高效处理任务。
与现有常见的任务调度器不同,Colossal-AI不是静态地通过GPU个数来判断任务规模,而是根据批大小来动态、自动管理每个任务.
通过演化算法,该任务调度器还能不断优化调度决策,更大程度提升GPU利用率。
评估结果表明,与当前最先进的方法相比,该方法在平均JCT (job completion time)上能够缩短45.6%的时间,优于现有的深度学习任务调度算法。
此外,这种自适应可扩展调度器还能通过NCCL网络通信实现高效的任务迁移。
文章插图
最后,消除冗余内存也是加速AI训练的一种解决思路。
在这方面,Colossal-AI使用了zero redundancy optimizer技术(简称ZeRO)。
这种方法主要通过切分优化器状态、梯度、模型参数,使GPU仅保存当前计算所需的部分,从而来消除数据并行、模型并行中存在的内存冗余。
尤其是在部署模型推理时,通过zero offload可以将模型卸载到CPU内存或硬盘,仅使用少量GPU资源,即可实现低成本部署前沿AI大模型。
综上不难看出,在技术层面Colossal-AI的加速效果非常明显。
而在应用层面,Colossal-AI的设计也顾及了能耗问题和易用性两个维度。
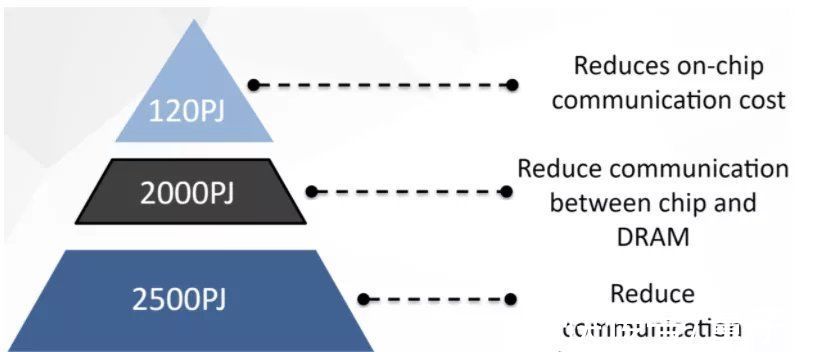
考虑到数据移动会是能耗的主要来源,Colossal-AI在不增加计算量的情况下尽可能减少数据移动量,以此来降低能耗。
文章插图
另一方面,作为一个开源给所有人使用的系统,Colossal-AI的使用门槛不高,即便是没有学习过分布式系统的人也能上手操作。
同时,只需要极少量的代码改动,Colossal-AI就能将已有的单机代码快速扩展到并行计算集群上。
最新实验结果释出Talk is cheap,效果如何,还是得把实验结果展开来看。
Colossal-AI近日释出的最新实验结果表明,这一大规模AI训练系统具有通用性,在GPT-3、GPT-2、ViT、BERT等流行模型上均有亮眼的加速表现。
注:以下GPU均指英伟达A100。
GPT-3训练速度提高10.7%英伟达的Megatron-LM在加速训练GPT-3时,至少需要128块GPU才能启动;而从下表可以看出,使用相同的计算资源,Colossal-AI可以将每次迭代花费的时间从43.1秒降至38.5秒。
- Java|Java培训:IntelliJ社区与终极版
- 产品经理|专访90+产品学社:产品经理的“精英化”趋势与求职培训行业现状
- 欧科云链2022年首场“警务培训”圆满结束 为全国民警普及区块
- 联合国训练研究所|我国“海丝一号”卫星助力汤加救灾
- javascript|Web前端培训:3个JavaScript 可视化框架
- 支付宝集五福|Java培训:在Java应用程序中测试微服务
- javascript|Web前端培训:前5个流行的 JavaScript IDE
- aiims|AIIMS基于ImmersiveTouch培训平台开展VR医疗手术
- Java|Java培训:Gradle、Maven和Ant概述
- 2022天象时间表