尤洋|2天训练出15亿参数大模型,国产开源项目力克英伟达Megatron-LM( 三 )
这也就意味着,Colossal-AI可以将GPT-3的训练速度进一步提高10.7%。
站在工程的角度,考虑到训练这样的大模型往往需要投入数百万美元,这一提升比例带来的收益不言而喻。
文章插图
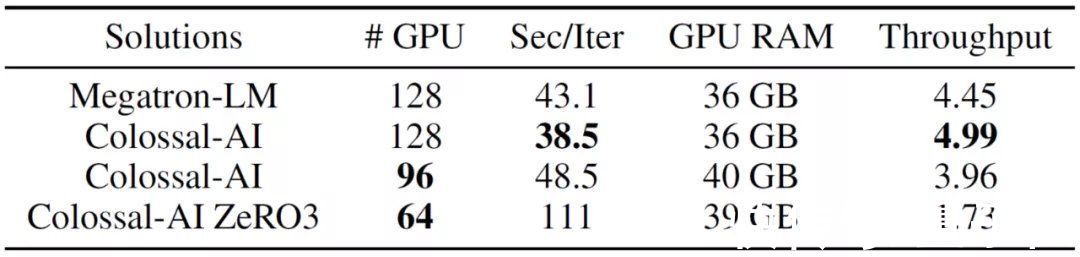
另外,通过系统优化,Colossal-AI还能在训练速度损失不大(43.1→48.5)的前提下,将GPU数量从128块减少到96块,大幅降低训练成本。
而进一步启用ZeRO3(零冗余优化器)后,所需GPU数量甚至能减少一半——至64块。
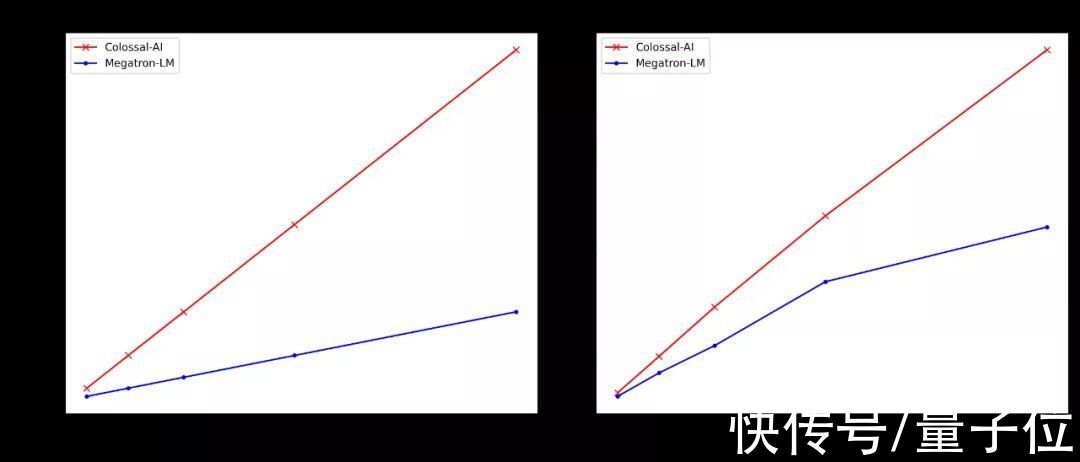
2天内可完成GPT-2训练在GPT-2的加速训练结果中,可以看到,无论是在4、16还是64块GPU的情况下,与Megatron-LM相比,Colossal-AI占用的显存都显著减少。

文章插图
也就是说,利用Colossal-AI,工程师们可以在采用同等数量GPU的前提下,训练规模更大的模型,或设置更大的批量大小来加速训练。
文章插图
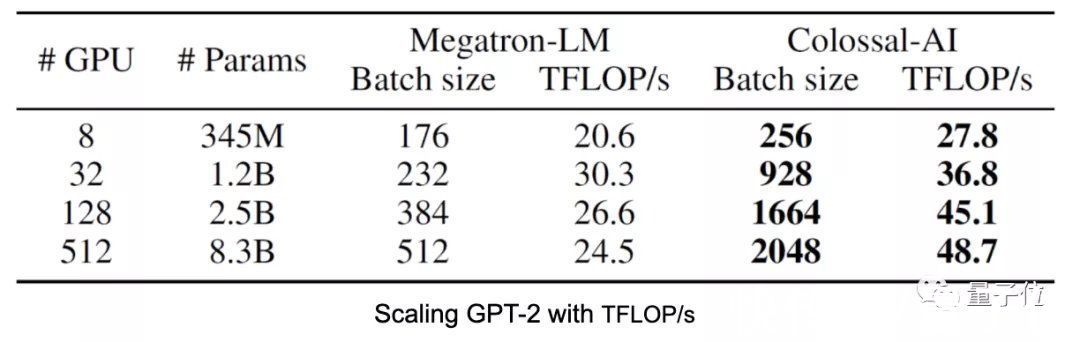
从下表结果中还可以看出,随着批量大小的增加,Colossal-AI的资源利用率会进一步提高,达到Megatron-LM速度的2倍。
文章插图
研发团队在256块GPU上进行了实验,最终用时82.8个小时完成了15亿参数版GPT-2的训练。
据此预估,后续在512块GPU上进行GPT-2预训练,Colossal-AI能将训练时间加速到45小时。
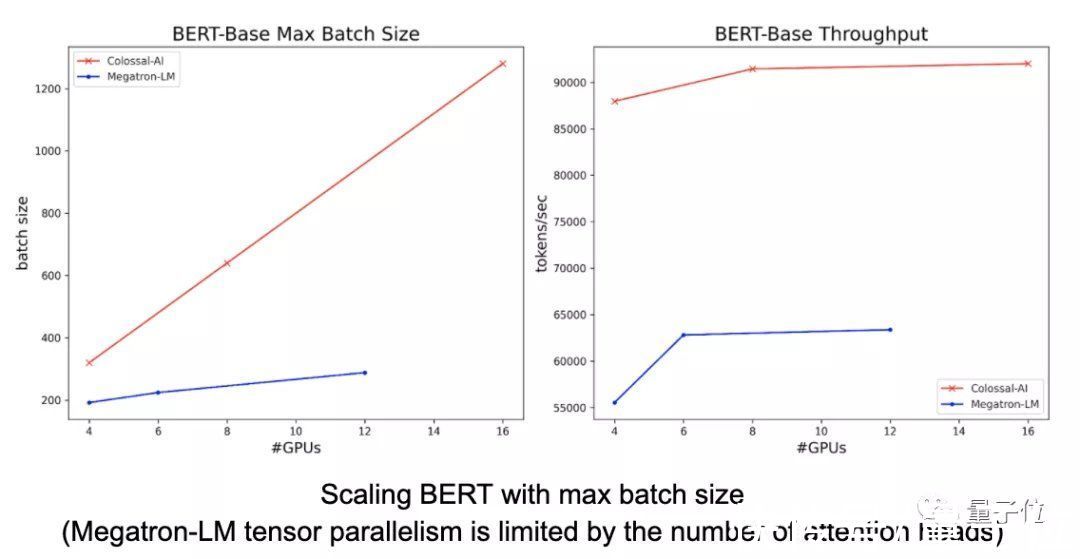
充分兼容多种并行模式在BERT上进行的实验,则体现了Colossal-AI作为世界上并行维度最多的AI训练系统的优势。
文章插图
【 尤洋|2天训练出15亿参数大模型,国产开源项目力克英伟达Megatron-LM】与Megatron-LM相比,Colossal-AI序列并行方法只需要更少的显存,就能够利用更大的批量大小来加速训练。同时,还允许开发者使用更长的序列数据。
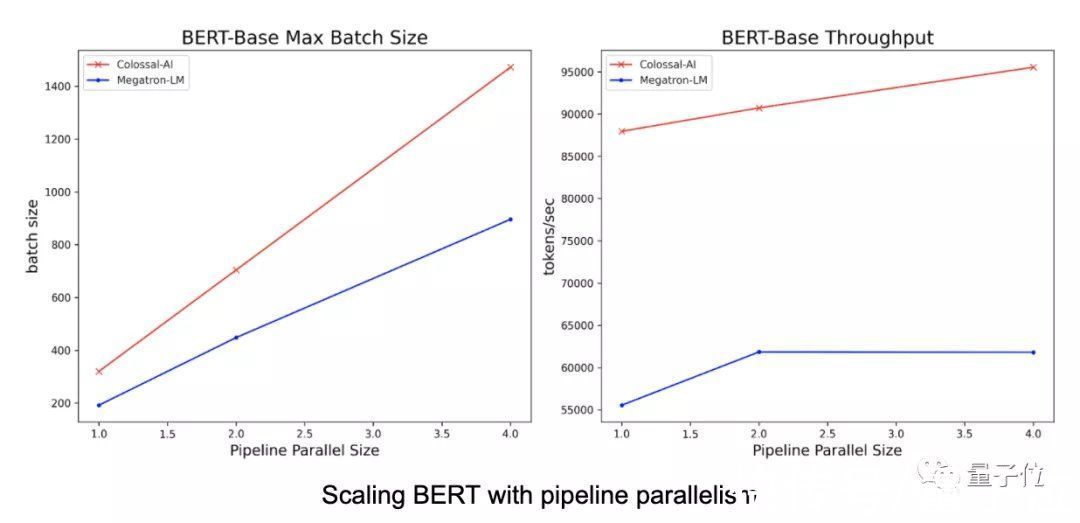
文章插图
Colossal-AI的序列并行方法还与流水并行方法兼容。当开发者同时使用序列并行和流水并行时,可以进一步节省训练大模型的时间。
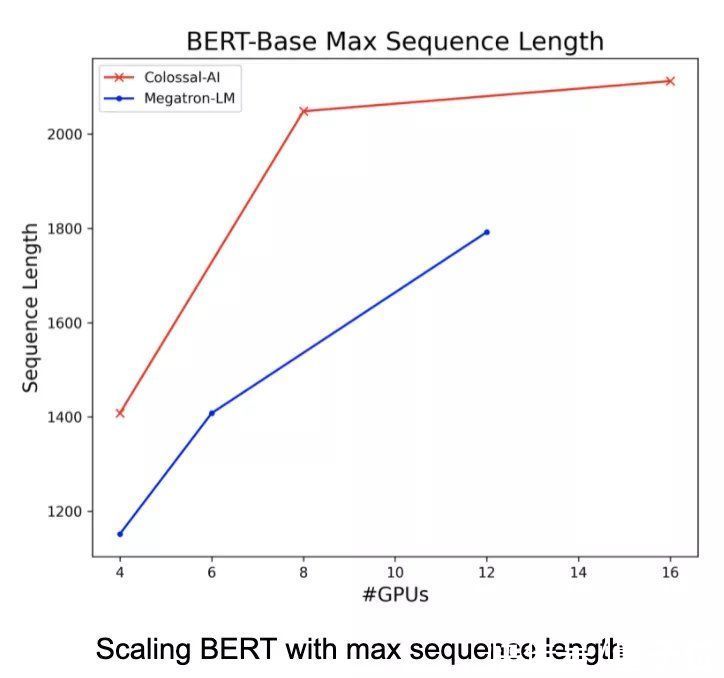
文章插图
另外,在近期的学术热点ViT模型上,Colossal-AI也展现了高维张量并行方法的优势。
在使用64张GPU的情况下,Colossal-AI采用2/2.5维方式进行张量并行,充分利用更大的批量大小,达到了更快的处理速度。
文章插图
背后团队:LAMB优化器作者尤洋领衔看到这里,是不是觉得Colossal-AI确实值得标星关注一发?
实际上,这一国产项目背后的研发团队来头不小。
领衔者,正是LAMB优化器的提出者尤洋。

文章插图
在谷歌实习期间,正是凭借LAMB,尤洋曾打破BERT预训练世界纪录。
据英伟达官方GitHub显示,LAMB比Adam优化器快出整整72倍。微软的DeepSpeed也采用了LAMB方法。
说回到尤洋本人,他曾以第一名的成绩保送清华计算机系硕士研究生,后赴加州大学伯克利分校攻读CS博士学位。
2020年博士毕业后,他加入新加坡国立大学计算机系,并于2021年1月成为校长青年教授(Presidential Young Professor)。
同样是在2021年,他还获得了IEEE-CS超算杰出新人奖。该奖项每年在全球范围内表彰不超过3人,仅授予在博士毕业5年之内,已在高性能计算领域做出有影响力的卓越贡献,并且可以为高性能计算的发展做出长期贡献的优秀青年学者。
- Java|Java培训:IntelliJ社区与终极版
- 产品经理|专访90+产品学社:产品经理的“精英化”趋势与求职培训行业现状
- 欧科云链2022年首场“警务培训”圆满结束 为全国民警普及区块
- 联合国训练研究所|我国“海丝一号”卫星助力汤加救灾
- javascript|Web前端培训:3个JavaScript 可视化框架
- 支付宝集五福|Java培训:在Java应用程序中测试微服务
- javascript|Web前端培训:前5个流行的 JavaScript IDE
- aiims|AIIMS基于ImmersiveTouch培训平台开展VR医疗手术
- Java|Java培训:Gradle、Maven和Ant概述
- 2022天象时间表