尤洋|2天训练出15亿参数大模型,国产开源项目力克英伟达Megatron-LM
鱼羊 明敏 发自 凹非寺
量子位 | 公众号 QbitAI
当今AI之势,影响纵深发展的矛盾是什么?
一方面,大模型风头正劲,效果惊艳,人人都想试试。但另一方面,硬件基础上动不动就是上万张GPU的大规模集群在日夜燃烧,钞能力劝退。
所以如果告诉你,现在只用一半数量的GPU,也能完成同样的GPT-3训练呢?
你会觉得关键钥匙是什么?
不卖关子了。实现如此提升的,是一个名为Colossal-AI的GitHub开源项目。
而且该项目开源不久,就迅速登上了Python方向的热榜世界第一。
文章插图
↑GitHub地址:https://github.com/hpcaitech/ColossalAI
不仅能加速GPT-3,对于GPT-2、ViT、BERT等多种模型,Colossal-AI的表现也都非常nice:
比如半小时左右就能预训练一遍ViT-Base/32,2天能训完15亿参数GPT模型、5天可训完83亿参数GPT模型。
与业内主流的AI并行系统——英伟达Megatron-LM相比,在同样使用512块GPU训练GPT-2模型时,Colossal-AI的加速比是其2倍。而在训练GPT-3时,更是可以节省近千万元的训练费用。
此外在训练GPT-2时,显存消耗甚至能控制在Megatron-LM的十分之一以下。
Colossal-AI究竟是如何做到的?
老规矩,我们从论文扒起。
高效6维并行方法简单来说,Colossal-AI就是一个整合了多种并行方法的系统,提供的功能包括多维并行、大规模优化器、自适应任务调度、消除冗余内存等。

文章插图
首先来看多维并行。
所谓“多维”是指,目前主流的分布式并行方案往往使用多种并行方法。
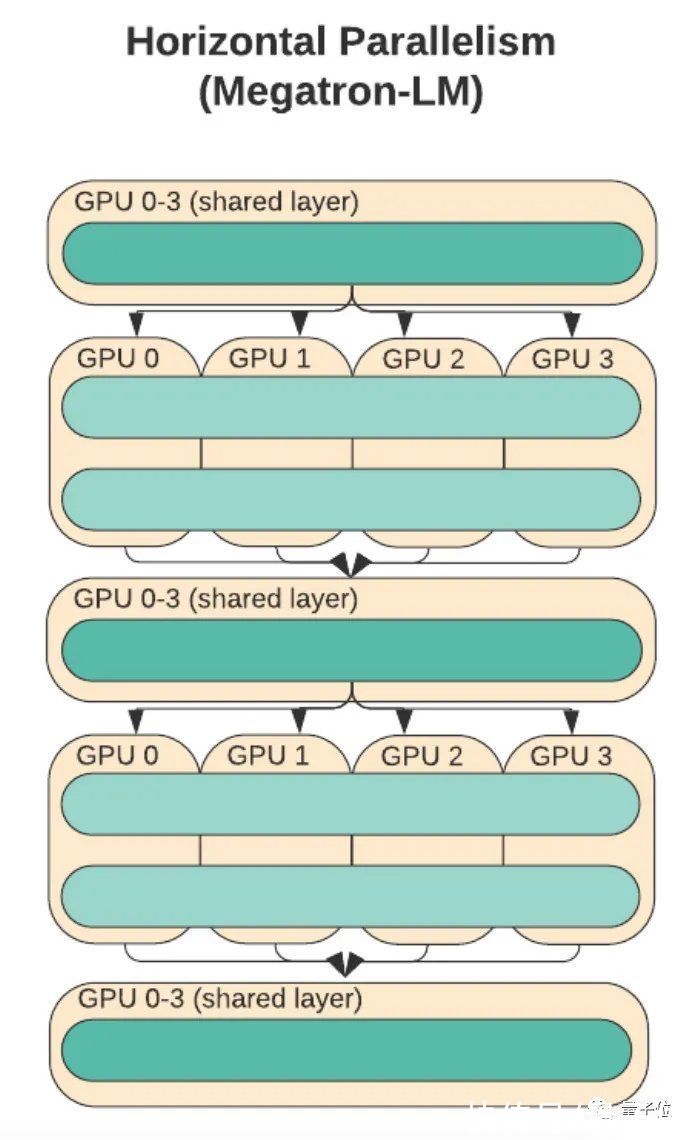
比如英伟达的Megatron-LM使用了3种方法:数据并行、流水并行和张量并行。因此这种模式也被称为三维并行。微软的DeepSpeed调用Megatron-LM作为并行基础。
而Colossal-AI能将系统的并行维度,一下子拉升到6维——
在兼容数据并行、流水并行的基础上,基于该项目团队自研的2维/2.5维/3维张量并行方法,以及序列并行实现。
其中,高维张量并行正是Colossal-AI提升大模型显存利用率和通信效率的关键所在。
其实张量并行并不新奇,只是过去我们常见的张量并行更多都是基于一维的。
它的原理是将模型层内的权重参数按行或列切分到不同的处理器上,利用分块矩阵乘法,将一个运算分布到多个处理器上同时进行。
比如英伟达的Megatron-LM就是一个典型的例子。
文章插图
但这种并行方式存在一定弊端。
比如,每个处理器仍需要存储整个中间激活,使得在处理大模型时会浪费大量显存空间。
另一方面,这种单线方法还会导致每个处理器都需要与其他所有处理器进行通信。
这意味着假设有100个GPU的话,每个GPU都需要与其他99个GPU通信,每次计算需要通信的次数就高达9900次。
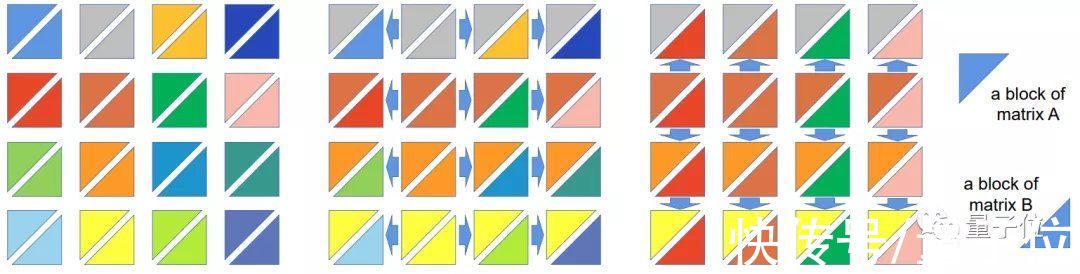
但如果将张量并行的维度扩展到2维,单次计算量能立刻下降一个量级。
因为每个GPU只需与自己同行或同列的GPU通信即可。
同样还是100个GPU的情况,每个GPU需要通信的GPU个数就能降到9个,单次计算仅需900次。
文章插图
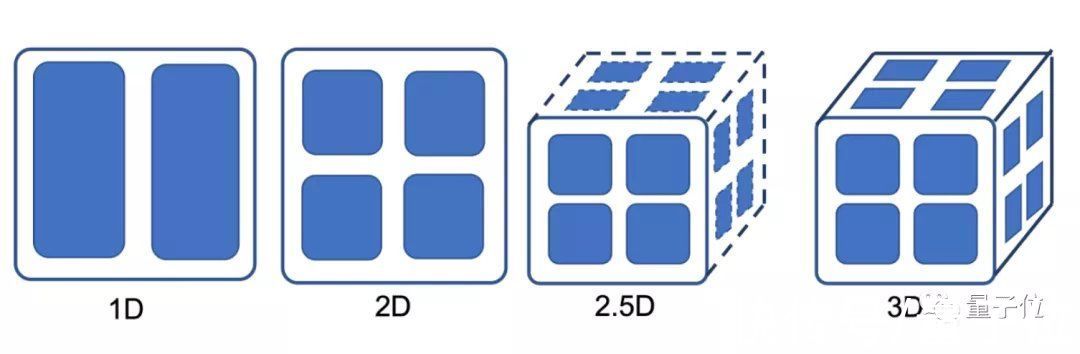
实际上在此基础上,Colossal-AI还包含2.5维、3维张量并行方法,可以进一步降低传输成本。
相较于2维并行方法,2.5维并行方法可提升1.45倍效率,3维方法可提升1.57倍。
文章插图
针对大图片、视频、长文本、长时间医疗监控等数据,Colossal-AI还使用了序列并行的方法,这种方法能突破原有机器能力限制,直接处理长序列数据。
- Java|Java培训:IntelliJ社区与终极版
- 产品经理|专访90+产品学社:产品经理的“精英化”趋势与求职培训行业现状
- 欧科云链2022年首场“警务培训”圆满结束 为全国民警普及区块
- 联合国训练研究所|我国“海丝一号”卫星助力汤加救灾
- javascript|Web前端培训:3个JavaScript 可视化框架
- 支付宝集五福|Java培训:在Java应用程序中测试微服务
- javascript|Web前端培训:前5个流行的 JavaScript IDE
- aiims|AIIMS基于ImmersiveTouch培训平台开展VR医疗手术
- Java|Java培训:Gradle、Maven和Ant概述
- 2022天象时间表