丰色 发自 凹非寺
量子位 | 公众号 QbitAI
最近,Meta AI推出了这样一个“杂食者”(Omnivore)模型,可以对不同视觉模态的数据进行分类,包括图像、视频和3D数据。

文章插图
比如面对最左边的图像,它可以从深度图、单视觉3D图和视频数据集中搜集出与之最匹配的结果。
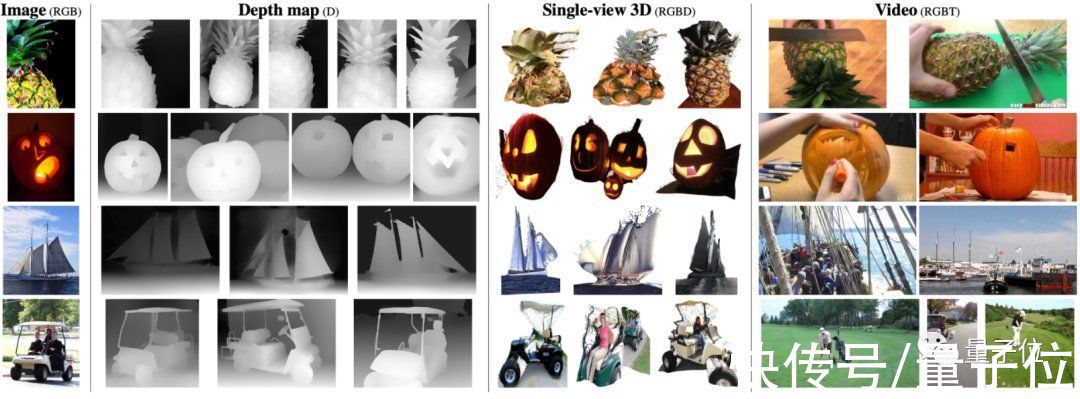
文章插图
这在之前,都要分用不同的模型来实现;现在一个模型就搞定了。
而且Omnivore易于训练,使用现成的标准数据集,就能让其性能达到与对应单模型相当甚至更高的水平。
实验结果显示,Omnivore在图像分类数据集ImageNet上能达到86.0%的精度,在用于动作识别的Kinetics数据集上能达84.1%,在用于单视图3D场景分类的SUN RGB-D也获得了67.1%。
另外,Omnivore在实现一切跨模态识别时,都无需访问模态之间的对应关系。
不同视觉模态都能通吃的“杂食者”Omnivore基于Transformer体系结构,具备该架构特有的灵活性,并针对不同模态的分类任务进行联合训练。
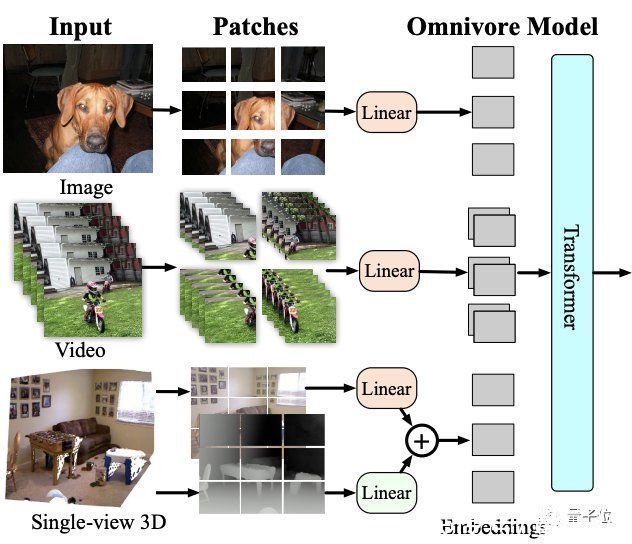
模型架构如下:
文章插图
Omnivore会将输入的图像、视频和单视图3D图像转换为embedding,并馈送到Transformer中。
虽然它可以使用任何vision transformer架构来处理patch embedding,但鉴于Swin transformer在图像和视频任务上的强大性能,这里就使用该架构作为基础模型。
具体来说,Omnivore将图像转为patch,视频转为时空tube(spatio-temporal tube),单视图3D图像转为RGB patch和深度patch。
然后使用线性层将patches映射到到embedding中。其中对RGB patch使用同一线性层,对深度patch使用单独的。
总的来说,就是通过embedding将所有视觉模式转换为通用格式,然后使用一系列时空注意力(attention)操作来构建不同视觉模式的统一表示。
研究人员在ImageNet-1K数据集、Kinetics-400数据集和SUN RGB-D数据集上联合训练出各种Omnivore模型。
这种方法类似于多任务学习和跨模态对齐,但有2点重要区别:
1、不假设输入观测值对齐(即不假设图像、视频和3D数据之间的对应关系);
2、也不假设这些数据集共享相同的标签空间(label space)。
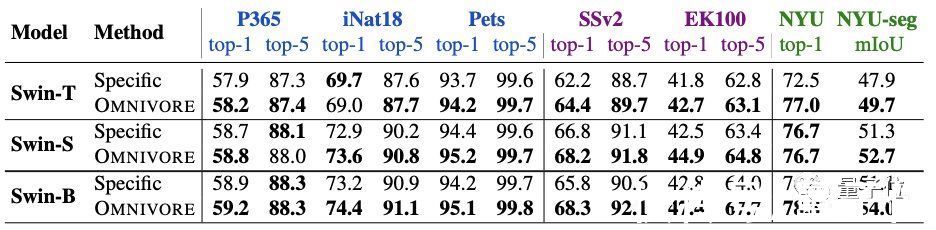
性能超SOTA实验方面,首先将Omnivore与各视觉模态对应的特定模型(下表中指Specific)进行比较。
一共有三种不同的模型尺寸:T、S和B。
预训练模型在七个下游任务上都进行了微调。
图像特定模型在IN1K上预训练。视频特定模型和单视图3D特定模型均使用预训练图像特定模型的inflation进行初始化,并分别在K400和SUN RGB-D上进行微调。
结果发现,Omnivore在几乎所有的下游任务上的性能都相当于或优于各特定模型。
其中尺寸最大的Swin-B实现了全部任务上的SOTA。
文章插图
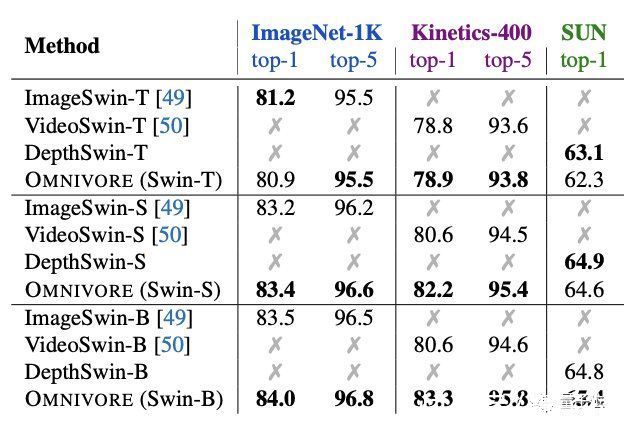
将Omnivore与具有相同模型架构和参数数量的特定模型比较也是相同的结果。
文章插图
其中Omnivore在IN1K、K400和SUN数据集上从头开始联合训练,而特定模态的模型针对每个数据集专门训练:
ImageSwin模型从零开始训练,VideoSwin和DepthSwin模型则从ImageSwin模型上进行微调。
接下来将Omnivore与图像、视频和3D数据分类任务上的SOTA模型进行比较。
结果仍然不错,Omnivore在所有预训练任务中都表现出了优于SOTA模型的性能(下图从上至下分别为图像、视频和3D数据)。
- meta|NFT周刊 | Meta计划推出NFT市场;Coinbase与万事达卡合作;网易推出数字藏品平台
- 二手机|华为又出奇招:推出这种产品,还被瞬间抢完
- AR|以色列公司推出新面部识别功能:戴着口罩也能识别
- 注册|中国联通推出" 注册清理服务通道 ",统一处理号码已注册信息
- 有品日报|奥兰中国获融资;吉利拟收购魅族手机;叮咚买菜推出自有烘焙品牌
- 约瑟夫·拜登|中国第二美国第九,拜登推出芯片法案,广纳英才与中国一争高下
- 小雷|再也不怕手机号被注册!国内运营商巨头推出新招:烦恼又少了一个
- Google|谷歌AR眼镜曝光:对抗苹果和Meta,谷歌进军元宇宙的序曲?
- iPhone或将推出新配色“中国红”,它能挽救苹果公司的销量吗?
- 本文转自:北京商报一则“娃哈哈推出宗帅家酱酒”的新闻让娃哈哈白酒再次进入到业内人士的视线...|时隔九年,娃哈哈再做酱酒,这次能成功吗?