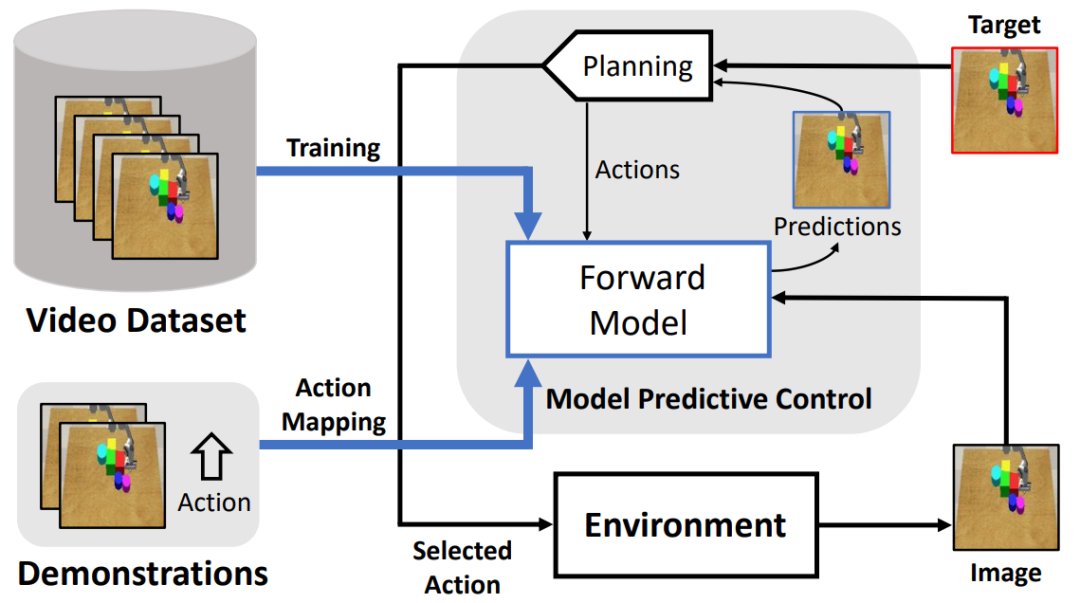
基于无监督学习环境模型的机器人运动控制|IROS 2021 | 模型( 三 )
文章插图
- 华为|问界M5风光无限,赛力斯SF5暗自神伤,华为或许低估了造车这事?
- iqoo|iQOO Z5x兼备长续航与优质好屏,无压力畅玩游戏
- 京东正式上线“年礼无忧”服务
- iPhoneSE|都是情怀!iPhone SE3外观毫无改变:A15处理器、支持5G
- 观光巴士|无人驾驶观光巴士走进湖滨
- 信息科学技术学院|瞧不起中国芯?芯片女神出手,30岁斩获国际大奖,让美国哑口无言
- 美通社|驭势科技与Teksbotics打造无人驾驶递送车现身沙特 | 阿卜杜拉
- 白白胖胖头顶起雾走走停停安全无误在哈尔滨站候车厅内一边消毒一边在室内移动的智能消毒机器人...|火车站里的机器人服务,是什么体验?
- ROG全球首款2K 360Hz显示器发布;努比亚开卖新音C1真无线耳机
- 年礼无忧|京东正式上线“年礼无忧”服务